脱 COUNT DISTINCT のススメ
こちらの記事は、AWS Analytics Advent Calendar 2022 の 11 日目のエントリーです。AWS のクラウドデータウェアハウスサービスである Amazon Redshift でクエリが遅いので高速化したいという話があり、チューニングした事例を書こうと思います。
- Redshift における自動チューニング
- それでもさらにチューニングが必要なとき
- データ分析クエリでよく使われる、COUNT DISTINCT
- 脱 COUNT DISTINCT のススメ(困ったときだけ)
Redshift における自動チューニング
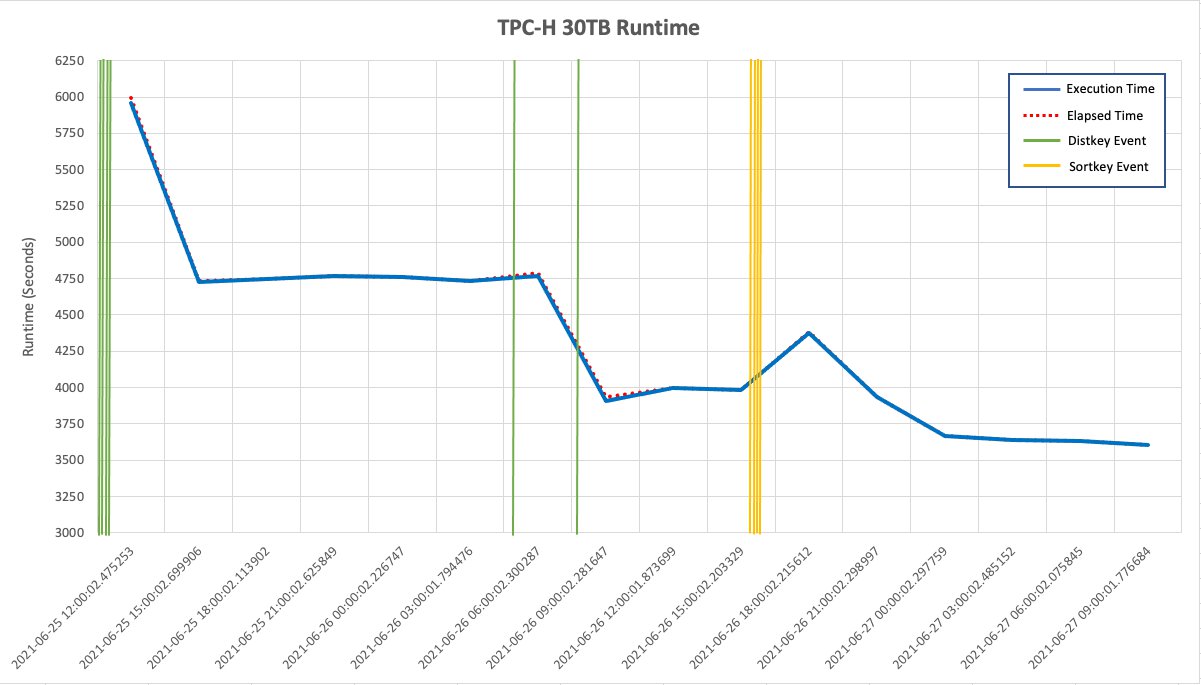
データウェアハウスを運用、あるいは利用していると実行に時間のかかるクエリに遭遇することはままあると思います。Redshift においては Automatic table optimization や Automated materialized views という機械学習の仕組みがエンジンに搭載されており、作られているテーブル定義や流れるワークロードをもとに、自動的にテーブルに格納されるデータの分散方式を変えたり(分散キー)、データを並び替えるキーを変えてくれたり(ソートキー)、マテリアライズドビューを作成してくれます。つまり、ワークロード環境にあったテーブル物理設計を自動で行い、クエリの高速化を手伝ってくれるというわけです。以下の "Automate your Amazon Redshift performance tuning with automatic table optimization | AWS Big Data Blog"で示されたグラフの例のように、時間の経過とともに分散キーの見直しが図られて実行時間が短縮し、その後さらにソートキーの見直しが図られて実行時間が短縮する、といった形ですね。このような仕組みがあるので、多くの場合は特に何もせずともいい感じに処理してくれるケースが多いはずです。
それでもさらにチューニングが必要なとき
とはいえ、これですべての問題が解決するとは限らないし、そもそもテーブル物理設計(分散キー、ソートキー、マテリアライズドビューなど)の変更だけでは限界があるケースもあります。そんな時にはクエリの書き方を見直すのも一つです。*1
分散キーとかソートキーとか、テーブル物理設計にまつわるチューニングの話は正式ドキュメントを含めいろいなところに情報が出ているけど、クエリ部分についてはあまり情報がない気がしたので、今回は、クエリチューニングの一例を紹介します。
データ分析クエリでよく使われる、COUNT DISTINCT
COUNT DISTINCT、それは分析クエリでもよく使われる存在にしてなかなか厄介なやつでございます。まぁ言わずもがなですが、ある列の値をもとに重複を排除して取り出してその数をカウントする処理で、基本的に重いと言われているやつですね。たとえば大量のアクセスユーザーログデータが格納されたテーブルから、ユニークユーザーの数を出すときなんかに使われます。
今回、Redshift 上を流れる長文クエリで非常に時間のかかっているものがあり、ボトルネック解析をしていたところ、特定のサブクエリの箇所で時間がかかっていそう、ということが分かりました。そのサブクエリの中身を見ると COUNT DISTINCT の処理が多用されていたため、ここを書き換えることで性能を改善しました。
このブログでは、事情により実際のクエリは書けないため、サンプルデータを使ってどのようにクエリを書き換えたかを記載します。
COUNT DISTINCT を GROUP BY + COUNT に変えてみた
サンプルデータとしては、標準ベンチマークの TPCH スキーマの lineitem テーブル(約60億件)を使います。
dev=# select count(*) from lineitem; count ------------ 5999989711 (1 row)
COUNT DISTINCT を含む元のクエリです。複数列で COUNT DISTINCT しています。
dev=# select l_linestatus, count(distinct l_shipdate), count(distinct l_commitdate), count(distinct l_receiptdate) from lineitem group by l_linestatus; l_linestatus | count | count | count --------------+-------+-------+------- F | 1263 | 1323 | 1292 O | 1263 | 1323 | 1292 (2 rows) Time: 208819.605 ms
208 秒くらいかかりました。
これを、GROUP BY + COUNT の処理に書き換えます。
dev=# select l_linestatus, count(l_shipdate), count(l_commitdate), count(l_receiptdate) from ( select l_linestatus, l_shipdate, null as l_commitdate, null as l_receiptdate from lineitem group by l_linestatus, l_shipdate union all select l_linestatus, null as l_shipdate, l_commitdate, null as l_receiptdate from lineitem group by l_linestatus, l_commitdate union all select l_linestatus, null as l_shipdate, null as l_commitdate, l_receiptdate from lineitem group by l_linestatus, l_receiptdate ) group by l_linestatus; l_linestatus | count | count | count --------------+-------+-------+------- F | 1263 | 1323 | 1292 O | 1263 | 1323 | 1292 (2 rows) Time: 94580.686 ms
94秒に短縮されました。返ってくる結果は COUNT DISTINCT のクエリと同じです。
これ、クエリが長くなって可読性は悪いですが、何をしているかというと
- まず最初に () で囲まれたサブクエリの中で DISTINCT を使わず GROUP BY を使って列ごとに重複排除
- それぞれを UNION で連結する
- UNION で連結した重複排除済みのデータをカウントする
という感じです。
おまけ1:APPROXIMATE COUNT DISTINCT
余談として、もし COUNT DISTINCT 結果に厳密な精度を求めない場合(ある程度ざっくりの傾向値でいいよ、という場合)は、HyperLogLog の仕組みを使った APPROXIMATE COUNT DISTINCT を使うのも手です。精度が落ちるかわりに、非常に高速に結果を返すことができます。
APPROXIMATE COUNT DISTINCT パターン
dev=# select l_linestatus, approximate count(distinct l_shipdate), approximate count(distinct l_commitdate), approximate count(distinct l_receiptdate) from lineitem group by l_linestatus; l_linestatus | count | count | count --------------+-------+-------+------- O | 1266 | 1330 | 1296 F | 1260 | 1315 | 1293 (2 rows) Time: 61995.861 ms
COUNT DISTINCT の結果と若干数値が異なりますが、61秒と非常に高速に結果を返しました。
おまけ2:1つの COUNT DISTINCT を含むクエリの書き換え
ここまでの例はクエリ内に複数の COUNT DISTINCT がある場合の書き換えでしたが、もし一つの COUNT DISTINCT がある場合なら、もう少しシンプルになります。
COUNT DISTINCT パターン
dev=# select l_linestatus, count(distinct l_shipmode) from lineitem group by l_linestatus; l_linestatus | count --------------+------- F | 7 O | 7 (2 rows) Time: 134243.333 ms
GROUP BY + COUNT パターン
dev=# select l_linestatus, count(l_shipmode) from ( select l_linestatus, l_shipmode from lineitem group by l_linestatus,l_shipmode ) group by l_linestatus; l_linestatus | count --------------+------- F | 7 O | 7 (2 rows) Time: 55941.845 ms
この例の場合だと、COUNT DISTINCT から GROUP BY + COUNT に書き換えることで、実行時間が134秒から55秒と、半分以下になりました。
脱 COUNT DISTINCT のススメ(困ったときだけ)
COUNT DISTINCT を GROUP BY + COUNT に変えることによって、パフォーマンス向上が確認できました。COUNT DISTINCT を使ったクエリのパフォーマンスにお困りの方は、脱 COUNT DISTINCT を試してみてはいかがでしょうか。
ただ、当たり前ですが念の為補足しておくと、COUNT DISTINCT を使っていてもそれほどパフォーマンスに困っていないなら、わざわざ書き換える必要はないです。Redshift のエンジンバージョンアップによって性能向上も期待できるし、なによりクエリの可読性も大事です。
また、何か書きたいと思います。See you next time!
*1:性能改善の手段としては、テーブル物理設計やクエリの見直しがすべてではなく、データモデル(テーブル論理設計)自体を見直す、リソースを増やす(Redshift Provisioned の場合はノード数を増やす、Redshift Serverless の場合は RPU を増やす)など他にももちろんあります、念の為…